FLOWWER enthält eine eingebaute OCR (Optical Character Recognition, deutsch: optische Zeichenerkennung), über welche die integrierte Eingabehilfe mit Daten versorgt wird. Diese Technologie wird vollständig auf unseren Servern, ohne externe Dienste oder Cloud-Services zu nutzen, ausgeführt. So bleiben alle Kundendaten unter unserer Kontrolle und gelangen nicht in potentiell unsichere Cloud-Systeme.
Die OCR ist standardmäßig in FLOWWER enthalten. Um sie nutzen zu können, muss die USt.-ID (Umsatzsteuer-Identifikationsnummer) in den Unternehmensdaten (siehe Basisdaten) eingetragen sein. FLOWWER unterscheidet Ihre ID anhand dieser Eingabe von der eines Lieferanten. Sollte Ihr Unternehmen keine USt.-ID haben und Sie möchten trotzdem die Datenextraktion nutzen, tragen Sie bitte „DE000000000“ ein. So erkennt FLOWWER, dass keine USt.-ID vorliegt.
Das Training der OCR erfolgt durch die Nutzung der Eingabehilfe bei der Belegbearbeitung. Je häufiger diese verwendet wird, desto präziser wird die Texterkennung. Wenn die Maus über ein Textelement des Belegs bewegt wird, zeigt FLOWWER den erkannten Text grün hinterlegt an. Wird das Element per Mausklick ausgewählt, bietet FLOWWER passende Datenfelder der Belegeigenschaften an. Der Benutzer entscheidet, welches Feld dem Text zugeordnet wird (z. B. „Belegdatum“). FLOWWER übernimmt das Datum und lernt gleichzeitig die Position des Datums für zukünftige Belege desselben Lieferanten.
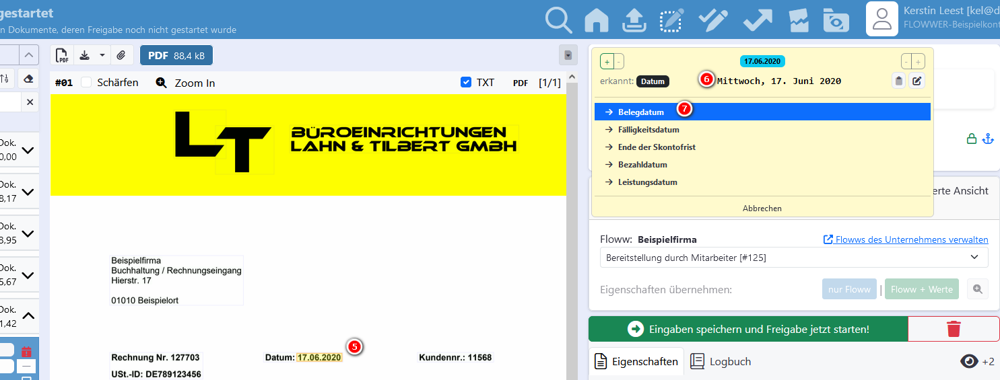
Wird ein weiterer Beleg desselben Lieferanten hochgeladen, erkennt FLOWWER den Lieferanten sowie das zuvor angelernte Datum und trägt es automatisch ein.
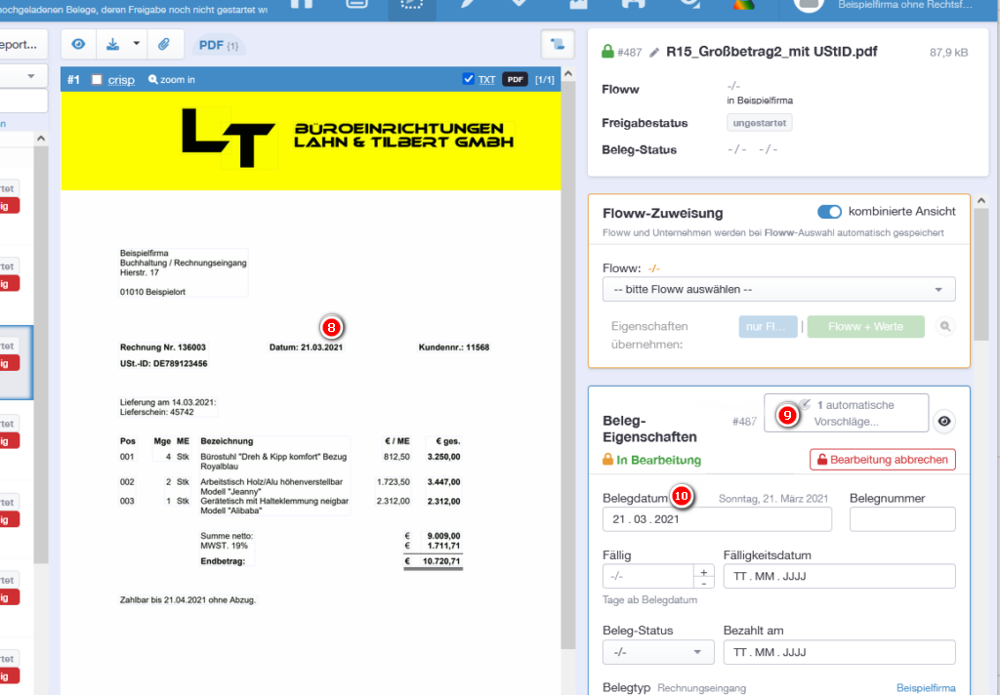
Alle erkannten Daten werden zur Kontrolle und möglichen Korrektur nochmals angezeigt. Die Option „Automatische Vorschläge“ ermöglicht es, die extrahierten Daten zu überprüfen und gegebenenfalls anzupassen, wodurch das OCR-Training weiter verfeinert wird.
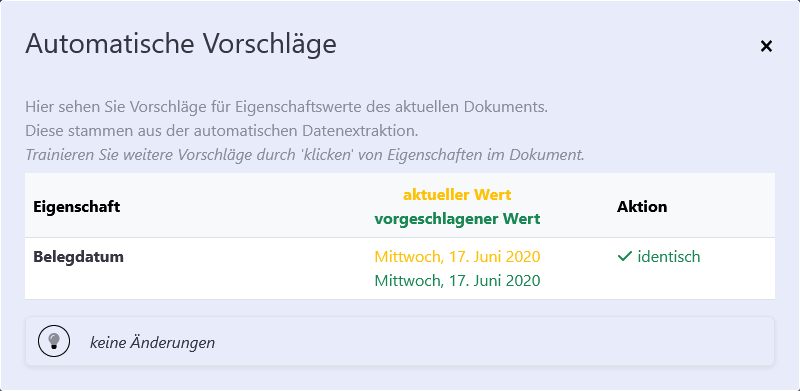
Durch kontinuierliche Anwendung wird die OCR von FLOWWER immer präziser und kann mehr Daten automatisch aus dem Belegbild extrahieren.
Volltextsuche
Zusätzlich zur Datenextraktion ermöglicht die OCR in FLOWWER die Erstellung eines Volltextindex.
Dadurch kann nicht nur nach Dokumenteigenschaften, sondern auch nach dem gesamten Inhalt eines Dokuments gesucht werden.
Dies bietet den Vorteil, dass auch Informationen gefunden werden können, die nicht explizit für die Suche vorgesehen waren.
Beispielsweise eine Seriennummer im Textkörper einer Rechnung.
Weitere Informationen finden Sie hier: Volltextsuche und Volltextindex
Anwendungsbereich
Die OCR-Funktionalität und Eingabehilfe in FLOWWER ist verfügbar für:
- Gescannte Dokumente (Papierbelege)
- Normale PDF-Dokumente
- E-Rechnungen aus PDFs (CII bzw. ZUGFeRD)
- E-Rechnungen aus XML (UBL)